 nltk.tag.pos_tag(tokens)
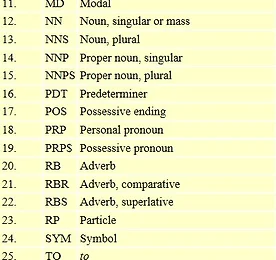
Use NLTK’s currently recommended part of speech tagger to tag the given list of tokens. >>> from nltk.tag import pos_tag >>> from nltk.tokenize import word_tokenize >>> pos_tag(word_tokenize("John's big idea isn't all that bad.")) [('John', 'NNP'), ("'s", 'POS'), ('big', 'JJ'), ('idea', 'NN'), ('is', 'VBZ'), ("n't", 'RB'), ('all', 'DT'), ('that', 'DT'), ('bad', 'JJ'), ('.', '.')] Alphabetical li..
더보기
nltk.tag.pos_tag(tokens)
Use NLTK’s currently recommended part of speech tagger to tag the given list of tokens. >>> from nltk.tag import pos_tag >>> from nltk.tokenize import word_tokenize >>> pos_tag(word_tokenize("John's big idea isn't all that bad.")) [('John', 'NNP'), ("'s", 'POS'), ('big', 'JJ'), ('idea', 'NN'), ('is', 'VBZ'), ("n't", 'RB'), ('all', 'DT'), ('that', 'DT'), ('bad', 'JJ'), ('.', '.')] Alphabetical li..
더보기
pandas.read_csv
pandas.read._csv: Read CSV (comma-separated) file into DataFrame. Also supports optionally iterating or breaking of the file into chunks. pandas.io.parsers.read_csv(filepath_or_buffer, sep=', ', dialect=None, compression=None, doublequote=True, escapechar=None, quotechar='"', quoting=0, skipinitialspace=False, lineterminator=None, header='infer', index_col=None, names=None, prefix=None, skiprows..
더보기
numpy.loadtxt vs. numpy.genfromtxt
numpy.loadtxt: Load data from a text file. Each row in the text file must have the same number of values. numpy.loadtxt(fname, dtype=, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0) numpy.genfromtxt: Load data with missing values handled as specified. numpy.genfromtxt(fname, dtype=, comments='#', delimiter=None, skiprows=0, skip_header=0, skip_foo..
더보기

